Big Data Engineer Resume Examples

Jul 18, 2024
|
12 min read
Craft a standout big data engineer resume: Tailor your experience, showcase your proficiency, and sift through technical skills to make your application truly shine. Don’t let your qualifications get lost in the database!
Rated by 348 people
- •Led the development and implementation of real-time data analytics solutions, reducing data processing time by 50%.
- •Managed a team of 5 data engineers, fostering collaboration that resulted in the successful launch of 4 major projects.
- •Designed and executed an ETL process that improved data accuracy and consistency, enhancing decision-making capabilities.
- •Conducted in-depth data analysis to identify trends and patterns, providing actionable insights that drove a 15% increase in revenue.
- •Implemented machine learning algorithms to automate data categorization, saving 200 hours of manual work annually.
- •Collaborated with cross-functional teams to integrate data solutions, ensuring a streamlined workflow and improved data governance.
- •Architected and maintained big data infrastructure to support large-scale data analysis, increasing query performance by 60%.
- •Developed and optimized data pipelines using Hadoop and Spark, reducing processing times by 25%.
- •Partnered with analytics teams to design data models that supported predictive analytics, driving a 12% increase in sales.
- •Implemented data security protocols, ensuring compliance with industry standards and reducing data breaches by 40%.
- •Provided technical guidance and training to junior engineers, enhancing team skill sets and productivity.
- •Developed data integration processes, consolidating data from multiple sources and improving data reliability by 30%.
- •Designed and built data warehouses, enabling efficient storage and retrieval of large datasets for complex queries.
- •Conducted performance tuning of SQL queries, achieving a 20% reduction in database load times.
- •Collaborated with business stakeholders to understand requirements and deliver solutions that aligned with business goals.
- •Conducted regular data quality assessments, identifying and resolving issues that improved data integrity by 15%.
- •Managed database systems, ensuring high availability and reliability for critical business applications.
- •Performed regular database maintenance, including backups, indexing, and performance optimization.
- •Monitored database performance and resolved issues proactively, reducing downtime by 18%.
- •Developed and implemented data migration strategies, ensuring smooth transitions with minimal disruption.


Machine Learning Big Data Engineer

Cloud-Based Big Data Engineer

Big Data Infrastructure Engineer
Advanced Analytics Big Data Engineer

Big Data Systems Engineer

Big Data Solutions Design Engineer

Real-Time Big Data Processing Engineer

Security Big Data Engineer

Hadoop Big Data Engineer

AI Big Data Engineer

Machine Learning Big Data Engineer resume sample
- •Led the design and implementation of data pipelines using Apache Spark, reducing data processing time by 35%.
- •Collaborated with data scientists to optimize machine learning models, improving model accuracy by 15%.
- •Integrated AWS cloud services, streamlining data ingest and storage, which cut operational costs by 20%.
- •Developed an automated monitoring system for real-time data integrity, resulting in a decrease in data errors by 40%.
- •Managed cross-functional teams to ensure seamless data integration, enhancing team productivity by 25%.
- •Pioneered new data analysis techniques that improved client insights into data trends and patterns.
- •Engineered scalable ETL solutions that increased the data pipeline throughput by 50%.
- •Worked with product managers to refine data accessibility, increasing data retrieval speeds by 40%.
- •Adopted cutting-edge data storage solutions that improved data retrieval time by 30%.
- •Implemented CI/CD practices, reducing deployment times for data engineering solutions by 25%.
- •Collaborated with stakeholders to standardize data quality protocols, enhancing data reliability by 20%.
- •Optimized the cloud-based data processing systems, increasing efficiency by 45% through application of Apache Flink.
- •Successfully implemented real-time data processing tasks, reducing data latency by 30%.
- •Researched and integrated new data science methodologies, which resulted in a 25% improvement in data analysis speed.
- •Coordinated with international teams to enhance data processing techniques, resulting in improved global project delivery.
- •Analyzed large datasets to assist in product development leading to a 20% increase in customer satisfaction.
- •Developed data visualization dashboards, improving data insights and reporting efficiency by 50%.
- •Streamlined data entry processes, reducing manual entry errors by 35%.
- •Participated in data governance protocols to ensure data security and compliance.
Cloud-Based Big Data Engineer resume sample
- •Led a team to design and implement a data pipeline on AWS, improving data ingestion speed by 40% and enabling faster analytics.
- •Developed automated ETL workflows with Python, resulting in a 25% reduction in manual processing time.
- •Collaborated with cross-functional teams to redesign data architecture, aligning with business objectives and enhancing team productivity.
- •Optimized cloud resource allocation, cutting down costs by 30% while maintaining service quality and reliability.
- •Monitored and proactively resolved data pipeline issues, reducing downtime by 35% and ensuring data accuracy.
- •Implemented comprehensive documentation practices, increasing process transparency and facilitating future training needs.
- •Designed scalable data storage solutions in Google Cloud, improving data query performance by 50% for analytical purposes.
- •Built robust ETL processes to ensure consistent and high-quality data from multiple sources, increasing access speed by 20%.
- •Led initiatives to optimize existing systems for performance and cost-efficiency, saving the company over $100,000 annually.
- •Implemented automation tools increasing the workflow efficiency by 30%, allowing the team to focus on more strategic tasks.
- •Engaged in continuous learning to stay ahead of industry trends, recommending innovative solutions that enhanced product offerings.
- •Built and maintained over 20 data pipelines in Azure, processing hundreds of terabytes of data daily with high efficiency.
- •Developed custom tools for data quality checks, enhancing data reliability and reducing error rates by 15%.
- •Optimized data storage architecture, resulting in a 25% reduction in retrieval times and enhancing user experience.
- •Collaborated extensively with data analysts to provide valuable insights from complex datasets, boosting decision-making accuracy.
- •Analyzed large datasets using SQL and Python, uncovering trends that drove strategic initiatives and resulted in a 20% increase in efficiency.
- •Worked with cross-functional teams to develop data solutions that aligned with business needs, enhancing project outcomes.
- •Contributed to the creation of data visualization dashboards in Tableau, leading to a 30% improvement in report accuracy.
- •Assisted in the development of data governance protocols, standardizing processes and ensuring compliance with industry regulations.
Big Data Infrastructure Engineer resume sample
- •Led a project deploying Apache Spark, improving data processing speed by 40%, enhancing real-time analytics capabilities.
- •Engineered a big data infrastructure using Hadoop clusters, reducing operational costs by 20% through optimized resource management.
- •Developed robust data ingestion pipelines for ETL processes, facilitating seamless data flow and improving data accuracy by 25%.
- •Implemented data governance protocols to maintain data integrity, ensuring compliance with industry regulations and reducing errors by 15%.
- •Collaborated with cross-functional teams to integrate cloud platforms, supporting scalable and secure data storage solutions.
- •Monitored and optimized big data workflows, achieving high system availability and minimizing downtime to less than 5% annually.
- •Developed scalable data solutions using Kafka, leading to a 50% increase in data processing capabilities.
- •Managed NoSQL databases, notably MongoDB, optimizing storage solutions and reducing data retrieval time by 30%.
- •Designed data architecture frameworks supporting cross-team projects, enhancing collaboration and project efficiency by 20%.
- •Implemented containerization with Docker for seamless deployment, shortening project delivery timelines by 15%.
- •Facilitated regular system audits, enhancing data security and ensuring compliance with stringent data protection standards.
- •Implemented Hadoop ecosystem for data analysis projects, resulting in an enhanced data processing workflow by 35%.
- •Conducted performance tuning on big data systems, improving processing speeds and resource utilization by 25%.
- •Streamlined ETL processes, resulting in increased data accuracy and processing speeds, ultimately reducing operational latency.
- •Provided technical guidance on data integration projects, ensuring alignment with business objectives and enhancing outcomes.
- •Designed scalable data infrastructures aligned with business needs, enhancing data-driven decision-making processes.
- •Developed Python scripts for data processing tasks, improving efficiency and reducing manual intervention by 45%.
- •Integrated Google Cloud tools to support scalable and secure data storage, enhancing project outcomes significantly.
- •Provided regular system updates and enhancements, maintaining operational excellence and high data accuracy standards.
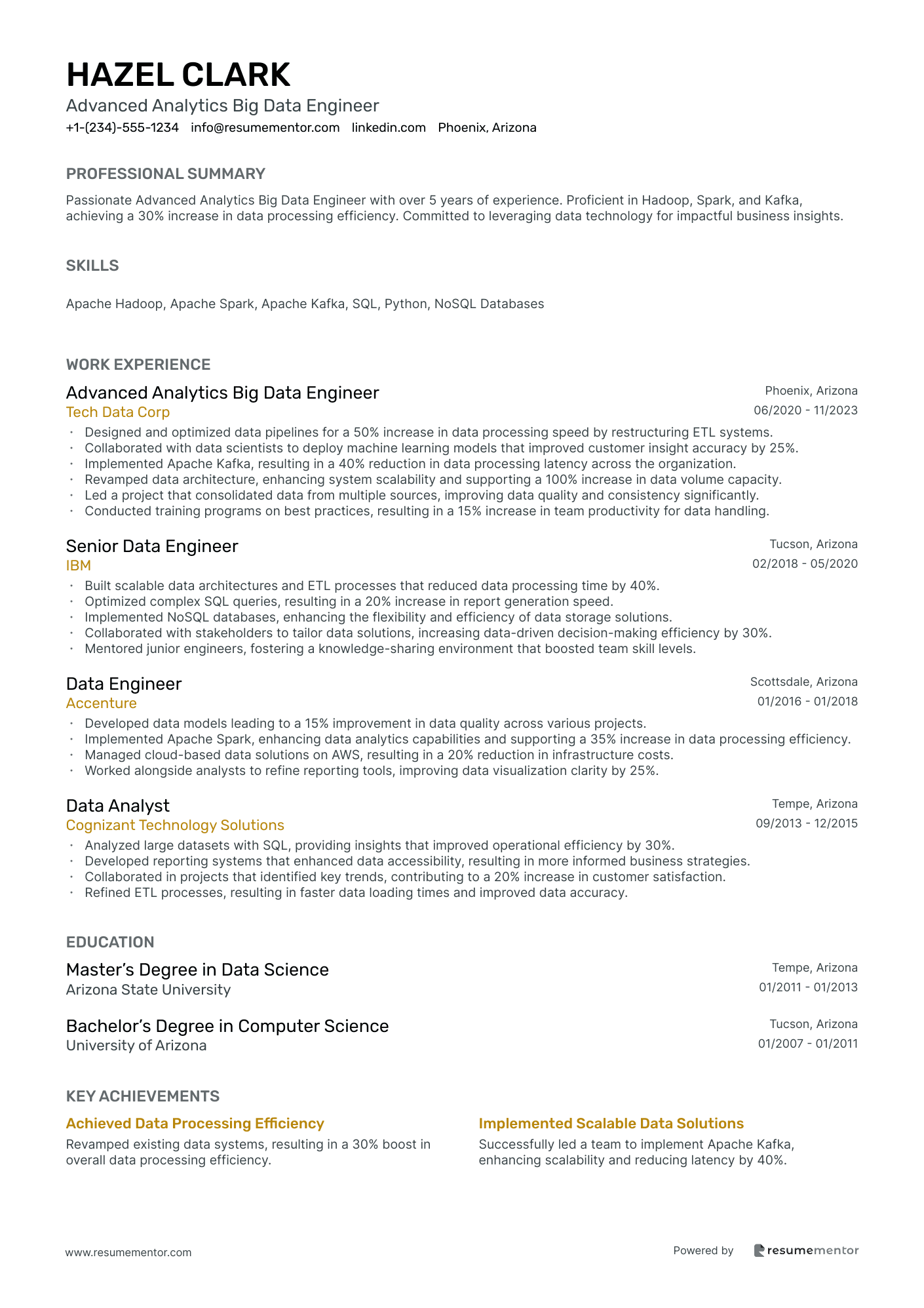
Advanced Analytics Big Data Engineer resume sample
- •Designed and optimized data pipelines for a 50% increase in data processing speed by restructuring ETL systems.
- •Collaborated with data scientists to deploy machine learning models that improved customer insight accuracy by 25%.
- •Implemented Apache Kafka, resulting in a 40% reduction in data processing latency across the organization.
- •Revamped data architecture, enhancing system scalability and supporting a 100% increase in data volume capacity.
- •Led a project that consolidated data from multiple sources, improving data quality and consistency significantly.
- •Conducted training programs on best practices, resulting in a 15% increase in team productivity for data handling.
- •Built scalable data architectures and ETL processes that reduced data processing time by 40%.
- •Optimized complex SQL queries, resulting in a 20% increase in report generation speed.
- •Implemented NoSQL databases, enhancing the flexibility and efficiency of data storage solutions.
- •Collaborated with stakeholders to tailor data solutions, increasing data-driven decision-making efficiency by 30%.
- •Mentored junior engineers, fostering a knowledge-sharing environment that boosted team skill levels.
- •Developed data models leading to a 15% improvement in data quality across various projects.
- •Implemented Apache Spark, enhancing data analytics capabilities and supporting a 35% increase in data processing efficiency.
- •Managed cloud-based data solutions on AWS, resulting in a 20% reduction in infrastructure costs.
- •Worked alongside analysts to refine reporting tools, improving data visualization clarity by 25%.
- •Analyzed large datasets with SQL, providing insights that improved operational efficiency by 30%.
- •Developed reporting systems that enhanced data accessibility, resulting in more informed business strategies.
- •Collaborated in projects that identified key trends, contributing to a 20% increase in customer satisfaction.
- •Refined ETL processes, resulting in faster data loading times and improved data accuracy.
Big Data Systems Engineer resume sample
- •Led a project integrating Hadoop with cloud storage, reducing data retrieval time by 25% and improving user access times.
- •Developed a Spark-based analytics platform that enhanced data processing speed by 40%, benefiting cross-functional data analysis teams.
- •Optimized a data pipeline for unstructured data ingestion, resulting in a 30% reduction in processing time and increased system efficiency.
- •Collaborated with five internal departments to implement data compliance protocol, ensuring 99.9% data integrity reliability.
- •Monitored and upgraded data systems infrastructure, resolving critical issues that improved system uptime by 15%.
- •Created comprehensive workflow documentation, facilitating onboarding and training, improving new hire effectiveness by 20%.
- •Implemented a Flink-based real-time data processing system, enhancing decision-making capabilities by reducing data latency by 50%.
- •Conducted code reviews, contributing to a 35% improvement in team code quality and project delivery deadlines.
- •Collaborated with data analysts to design an ETL workflow, increasing data extraction efficiency by 40%.
- •Integrated AWS services for scalable data storage solutions, increasing data handling capacity by 200 terabytes.
- •Led the integration of a new NoSQL database, achieving data processing scalability and improving system performance metrics.
- •Architected and maintained HDFS data storage systems, enhancing system capacity by 15% without increasing latency.
- •Devised data integrity protocols, significantly reducing error rates in data processing pipelines by 20%.
- •Collaborated with cross-functional teams to address data science requirements, creating solutions with a 25% increase in model accuracy.
- •Contributed to the evaluation of new technology adoptions, advising on the integration of data warehousing solutions.
- •Developed a SQL-based data analytics platform, improving query response time by 30% through optimized database indexing.
- •Participated in the design of data flow processes, resulting in a streamlined workflow that reduced processing overhead by 15%.
- •Championed cloud integration projects that expanded the data platform's scalability to handle 50% additional data volume.
- •Assisted in training new hires on data modeling and ETL processes, enhancing team capability and performance metrics.
Big Data Solutions Design Engineer resume sample
- •Led the design and implementation of a big data processing framework, enhancing data processing speed by 30%, resulting in more timely analytics.
- •Collaborated effectively across departments to streamline data pipelines, integrating over 10 diverse data sources into a centralized platform.
- •Pioneered data governance and quality assurance processes that decreased data errors by 25%, increasing confidence in analytics output.
- •Managed and optimized cloud resources, reducing operational costs by 20% while maintaining high application performance.
- •Mentored a team of 6 junior engineers in big data best practices and technologies, fast-tracking project delivery timelines.
- •Implemented a data warehousing solution that supported an increase of 40% in data volume for reporting needs.
- •Architected data models and databases supporting a 15% increase in query performance for cross-platform analytics.
- •Developed scalable data processing pipelines using Google Cloud services, enhancing real-time data processing by 20%.
- •Coordinated with analysts to turn complex data into understandable insights, improving report generation speed by 35%.
- •Implemented ETL processes which improved data cleanliness and usability, leading to more reliable forecasting models.
- •Stayed at the forefront of big data technology advancements by attending industry conferences and workshops.
- •Designed cloud-based data solutions on Azure, resulting in a 50% reduction in on-premise infrastructure costs.
- •Optimized data extraction processes from multiple data sources, leading to a 25% decrease in data retrieval time.
- •Facilitated a company-wide transition to new data visualization tools, increasing data accessibility for stakeholders.
- •Created thorough documentation for data architecture, enhancing team knowledge sharing and project onboarding.
- •Enhanced data processing frameworks using Hadoop and Spark, leading to a 40% increase in data processing capabilities.
- •Implemented NoSQL databases which improved data storage efficiency and access speed by 30%.
- •Contributed to the successful deployment of a high-availability data solution that sustained 99.9% uptime.
- •Collaborated in cross-functional teams to ensure alignment of data solutions with business strategies.
Real-Time Big Data Processing Engineer resume sample
- •Led a team to revamp the ETL pipeline, enhancing processing speed by 45% and reducing resource requirements by 20%.
- •Developed real-time processing frameworks with Apache Kafka, increasing real-time data ingestion capabilities by 40%.
- •Collaborated with cross-functional teams of data scientists and developers to implement a data processing system, leading to a 30% improvement in reporting accuracy.
- •Designed and optimized resources for a distributed computing environment, achieving a 25% increase in data throughput.
- •Resolved critical data quality issues by implementing a robust monitoring system, decreasing errors by 50%.
- •Initiated and managed the transition to cloud-based storage solutions, resulting in a 35% cost reduction in data storage.
- •Spearheaded the design and implementation of scalable data processing systems, achieving 99.9% uptime and reliability.
- •Optimized Spark and Kafka data pipelines, reducing latency by up to 50% during peak traffic periods.
- •Collaborated with application developers to align data solutions with business needs, improving delivery time by 25%.
- •Improved data processing and storage strategies across distributed environments, leading to a 20% improvement in performance.
- •Implemented machine learning algorithms within the data processing system, enhancing data analytics capabilities by over 30%.
- •Managed Hadoop clusters and optimized storage solutions, leading to a significant reduction in data retrieval time.
- •Designed and maintained real-time data processing frameworks, enhancing overall system efficiency by 25%.
- •Provided technical support for data processing systems and resolved high-priority issues, boosting team productivity.
- •Collaborated on a project that unified disparate data sources, increasing data accessibility and quality by 40%.
- •Analyzed data pipelines and processes, recommending improvements that increased data flow efficiency by 20%.
- •Implemented a monitoring system that proactively identified data inconsistencies, reducing incidents by 35%.
- •Worked closely with stakeholders to understand data needs, resulting in a 30% faster reporting process.
- •Optimized data models for better performance, strengthening the foundation for scalable data solutions.
Security Big Data Engineer resume sample
- •Designed and maintained data pipelines handling over 3 terabytes of security data daily, optimizing processing time by 25%.
- •Collaborated with security teams to develop real-time analytics, increasing threat detection efficiency by 30%.
- •Implemented robust data integrity protocols, resulting in a 20% reduction in false positives in security alerts.
- •Built real-time dashboards for dynamic security insights, reducing incident response times by 40%.
- •Developed scalable solutions using Spark and Kafka, streamlining data ingestion for new security feeds by 50%.
- •Provided analytics support during security incidents, reducing operational impact and downtime by 15%.
- •Engineered big data solutions to enhance cybersecurity monitoring, leading to a 35% improvement in anomaly detection.
- •Spearheaded development of secure data ingestion processes, increasing data quality compliance by 30%.
- •Optimized Hadoop clusters to process security logs efficiently, resulting in a 20% cost reduction in data infrastructure.
- •Collaborated with teams to integrate machine learning models into security workflows, boosting predictive accuracy by 25%.
- •Created visualizations utilizing Tableau to convey security insights, facilitating better decision-making for executives.
- •Implemented data ingestion frameworks using Kafka, improving data processing speed by 40% for security applications.
- •Developed real-time processing systems that analyzed over 1 million security events monthly, increasing threat visibility.
- •Participated in developing a SIEM system, achieving a 15% rise in automated cyber threat detection.
- •Collaborated with cross-functional teams to ensure data security compliance, reducing risk exposure substantially.
- •Assisted in data analytics for security projects, contributing to a 20% increase in data-driven decision making.
- •Managed and secured large datasets, improving data retrieval processes by 30%.
- •Supported incident response teams by providing crucial data insights, enhancing crisis management capabilities.
- •Worked on increasing the data integrity of security logs, which reduced errors in threat analysis reports by 25%.
Hadoop Big Data Engineer resume sample
- •Designed and maintained over 100 Hadoop-based data pipelines, resulting in a 40% increase in data processing efficiency.
- •Collaborated with data science teams to integrate new analytics models, improving forecast accuracy by 20%.
- •Optimized existing Hadoop workflows, reducing resource usage by 30% and cutting costs significantly.
- •Conducted regular data quality audits, raising data integrity to 99% through comprehensive validation processes.
- •Provided 24/7 support for Hadoop clusters, reducing downtime to less than 1% over a two-year period.
- •Developed detailed documentation for big data architecture and processes, enhancing team efficiency by 25%.
- •Implemented ETL processes using Hadoop and Spark, which improved data pipeline productivity by 35%.
- •Worked with data analysts to understand their needs, creating a data model that increased data accessibility by 50%.
- •Led a team to migrate on-premise data to AWS cloud, enhancing storage efficiency by 60%.
- •Established data warehousing best practices, resulting in a 20% reduction in data retrieval times.
- •Analyzed large data sets using Hadoop and Hive, providing insights that increased business revenue by 10%.
- •Developed scalable Hadoop solutions with YARN, improving client data processing capacity by 200%.
- •Integrated Hadoop with Flink for stream processing, which enhanced real-time data analysis capabilities by 25%.
- •Maintained HDFS clusters, achieving 99.99% uptime and reliability.
- •Piloted a cross-functional team project that reduced data redundancy by 15% across departments.
- •Wrote high-efficiency Java code for data manipulation, which improved system performance by 30%.
- •Collaborated in developing a data visualization tool that enhanced data interpretation by 35%.
- •Implemented code optimization techniques, reducing software bugs by 40%.
- •Provided key input to a project that improved the data indexing process, reducing retrieval time by 20%.
AI Big Data Engineer resume sample
- •Developed and maintained big data pipelines with Apache Spark, improving data processing speed by 40%, leading to improved data analytics capabilities.
- •Collaborated with data scientists to deploy machine learning models in production, reducing data retrieval times by 30% and streamlining AI operations.
- •Implemented robust data governance policies, ensuring 100% compliance with GDPR and CCPA regulations, safeguarding critical business data.
- •Optimized complex SQL queries, enhancing query execution speed by 25%, which significantly improved overall system performance.
- •Maintained high availability of data platforms by implementing automated system health checks, reducing downtime by 20%.
- •Conducted in-depth data analysis generating actionable insights, increasing operational efficiency of key business processes by 15%.
- •Engineered scalable data pipelines with Kafka and Hadoop for real-time data processing, doubling data throughput capacity, and enhancing analytics speed.
- •Integrated TensorFlow models into data workflows, resulting in a 50% increase in AI system prediction accuracy and reliability.
- •Optimized data architectures, cutting down data storage costs by 20% without sacrificing performance or data integrity.
- •Ensured high reliability of existing systems by implementing advanced monitoring solutions, reducing incident response times by 30%.
- •Collaborated with cross-functional teams on data-driven projects, enhancing product development cycles with comprehensive data insights.
- •Designed and implemented end-to-end data processing systems, cutting data processing times by 40% using advanced algorithms and distributed computing.
- •Successfully managed and upgraded SQL and NoSQL databases, increasing data access efficiency by 25% and supporting seamless data analytics operations.
- •Developed machine learning pipeline integrations, increasing processing efficiency by integrating scikit-learn workflows.
- •Implemented CI/CD practices, reducing new feature release cycle time by 30% and ensuring continuous delivery of data solutions.
- •Developed database optimization strategies, improving query performance by 35% and data retrieval speed across multiple systems.
- •Implemented data governance framework resulting in meticulous adherence to data privacy laws, safeguarding critical client information.
- •Led a project modernizing legacy systems, integrating cloud-based solutions, and resulting in a 25% reduction in system maintenance costs.
- •Efficiently managed database systems leading to minimized data loss incidents, significantly improving data reliability and trustworthiness.

Crafting a resume as a big data engineer can feel like distilling an ocean of information into a single, compelling glass of water. As the first impression potential employers get of you, it must effectively capture your technical strengths and present them clearly. In the vast field of big data engineering, organizing and highlighting your skills and experiences is essential to stand out.
This industry is competitive, so your resume needs to showcase your unique blend of data mastery and analytical precision. Think of your resume as a guide, leading you to roles that match your ambitions and skills. However, condensing years of technical work into a single page can be a daunting task.
To make this process easier, consider using a resume template. It helps ensure you include all relevant details in a polished, professional manner. Check out these resume templates to streamline your creation process. The right template allows you to arrange your skills, projects, and certifications in a way that resonates with hiring managers and connects with their needs.
By crafting a resume that reflects what you offer, you demonstrate why you are the best candidate for your next big data engineering role. Let’s dive into the steps to create a resume that not only opens doors but also helps you walk confidently through them.
Key Takeaways
- Organize your big data engineer resume to highlight your technical prowess and ability to manage and analyze large datasets effectively, including expertise in tools like Hadoop, Spark, and SQL.
- Use a chronological resume format showcasing your work experience and achievements to quickly convey your career progression and how past roles align with the job you're seeking.
- Ensure your resume is visually appealing and maintains formatting integrity by using modern fonts and saving the final version as a PDF.
- Structure your experience section to focus on quantifiable achievements, use impactful action verbs, and provide context with location and dates to highlight professional growth.
- Include a dedicated skills section with relevant technical and interpersonal skills, and tailor additional resume sections like certifications and education to emphasize strengths and commitment to ongoing learning.
What to focus on when writing your big data engineer resume
A big data engineer resume should clearly show the recruiter your ability to manage and analyze large datasets—communicating how you can build scalable data systems that impact business decisions is crucial. Highlighting your expertise with tools like Hadoop, Spark, and SQL is essential while also showcasing your problem-solving skills and ability to work collaboratively. Ensuring data accuracy and driving actionable insights should be central themes in your resume.
How to structure your big data engineer resume
- Contact Information: Make sure your contact information is complete and up to date—this means including your full name, phone number, email address, and a professional LinkedIn profile. Your LinkedIn should reflect recent projects and skills, as recruiters often cross-check this platform for additional credibility.
- Professional Summary: Your professional summary should be a snapshot of your career that highlights your experience and expertise in data engineering. Focus on mentioning specific projects where you made significant contributions to data system efficiencies and insights. This summary is your chance to grab attention by articulating how your skills align with the demands of a big data engineer role.
- Technical Skills: List relevant programming languages, software, and tools such as Python, Java, Hadoop, Spark, SQL, AWS, and Kafka—certifications that validate your proficiency in these areas can enhance your resume. Be specific about each tool or language's impact on your previous projects, ensuring that every technical skill you mention is actively used in the industry.
- Work Experience: Detail your experience with a focus on results-driven achievements—start with your most recent role and provide the company name, role, and employment dates. Highlight significant projects and prioritize achievements that had a measurable impact, whether that meant improving data processing speed, enhancing accuracy, or other business-critical results.
- Education: List your educational background with the degree, institution, and graduation date. Mention coursework relevant to data science or engineering, as higher education often aligns theory with practical applications in real-world scenarios. This connection enhances your credibility as a candidate who understands foundational and advanced aspects of big data.
- Projects: Highlight key projects by detailing your role, the tools used, and the outcomes achieved. Focus on projects that demonstrate your innovation and ability to solve complex challenges, as these examples showcase your practical application of big data skills. Transitioning into the final section, we will explore each area with more depth to ensure your resume format impresses recruiters at every stage.
Which resume format to choose
Crafting a resume as a big data engineer involves tailoring your presentation to highlight your skills and industry expertise. A chronological format is highly effective in achieving this, as it showcases your work experience and key accomplishments in a timeline. This approach helps prospective employers quickly understand your career progression and how your past roles align with the job you're seeking.
The choice of font can significantly impact the first impression your resume makes. Using fonts like Lato, Montserrat, or Raleway provides a modern and clean look. These fonts are not only visually appealing but also enhance readability, ensuring that your content is easy to digest without distracting from the key information you want to convey.
Always save your resume as a PDF to maintain the integrity of your formatting. PDFs ensure that your document looks professional and remains intact across all devices and operating systems. This consistency is crucial, as it reflects your attention to detail and ensures your resume is viewed exactly as you intended.
Standard margins, ideally about one inch on all sides, play a crucial role in your resume's readability and overall appearance. They provide a clean layout that makes the document easy to scan, which is important when recruiters and hiring managers often spend only a few seconds on an initial review. Proper margins also ensure your document looks well-organized if printed, presenting a polished and professional image that can set you apart in the competitive field of big data engineering.
How to write a quantifiable resume experience section
The experience section of your resume is key to showing how your skills as a big data engineer translate into real-world success. By focusing on quantifiable achievements, you make your impact clear to employers. Organizing your experience in reverse chronological order helps paint a picture of your professional growth, beginning with your most recent role. If you include the last 10-15 years, you can highlight the titles and responsibilities that best illustrate your career progression and areas of expertise. This approach ensures that your experience is tailored to the job ad, using keywords and action verbs like "optimized," "implemented," and "developed" to align with the role's requirements. Here’s an example of a standout experience section:
 03/2018 - 08/2023
03/2018 - 08/2023 
- •Implemented a data pipeline that reduced data processing time by 40%.
- •Developed and maintained a scalable data warehouse, leading to a 30% increase in query performance.
- •Collaborated with cross-functional teams to integrate new data sources, improving data accuracy by 20%.
- •Automated ETL processes, saving the team 15 hours per week in manual data handling.
This example highlights the power of using specific numbers to communicate your achievements, making your contributions easy to understand. By starting each bullet with dynamic verbs, you emphasize your role in driving improvements and fostering innovation. The details reflect your ability to meet industry demands and solve complex problems effectively. Including location and dates gives context to your roles, helping employers see your career trajectory clearly. Tailoring these elements with the right words shows you’re not only experienced but also aligned with the job you’re applying for, creating a focused narrative that’s compelling to potential employers.
Project-Focused resume experience section
A project-focused big data engineer resume experience section should effectively showcase your skills and achievements to stand out in the job market. Start by clearly listing the dates for each project to highlight your timeline of involvement. Use strong action words to vividly describe your contributions, ensuring complex roles are easy to understand. This clarity helps demonstrate both your technical prowess and problem-solving capabilities.
Concentrate on projects where you made measurable impacts, such as implementing innovative data solutions or optimizing existing processes. Detail your expertise with big data tools and technologies, emphasizing your role in overcoming specific challenges. Utilize figures or statistics to bring credibility and underscore the results of your work. Group related experiences into cohesive categories for enhanced readability. This structured approach not only strengthens the narrative of your project experience but also showcases your potential to make a meaningful impact in any organization.
Senior Big Data Engineer
Tech Innovations Inc.
June 2021 - December 2022
- Led a team to enhance data processing speeds by 35% through the implementation of Apache Kafka.
- Streamlined ETL processes using Apache Nifi, reducing data ingestion time by 50%.
- Developed a monitoring system that cut data anomalies by 70% using real-time dashboards.
- Collaborated with data scientists to integrate machine learning models, improving data accuracy by 20%.
Result-Focused resume experience section
A result-focused big data engineer resume experience section should showcase the significant impact you’ve made in your previous roles. Begin by emphasizing how you’ve enhanced processes, brought in innovations, and improved overall efficiency. Highlight concrete outcomes such as cost savings, time reductions, or increased data processing speed, as these details effectively demonstrate your problem-solving abilities and technical expertise.
Organize your experience to facilitate easy readability. Include your job title, workplace, and employment dates upfront. Use bullet points to clearly outline your key accomplishments and responsibilities, allowing hiring managers to quickly grasp your experience and skills. If teamwork was involved, describe your role to highlight your leadership and collaboration skills. Aim for active and concise language, avoiding complex jargon to keep the information clear and engaging.
Big Data Engineer
DataTech Solutions
January 2020 - August 2023
- Designed and implemented a data processing pipeline, cutting processing time by 40%.
- Led a team of data engineers to migrate 2 PB of data to cloud storage, enhancing accessibility and security.
- Collaborated with cross-functional teams to integrate machine learning models, boosting prediction accuracy by 25%.
- Optimized storage solutions to achieve a 30% reduction in data storage costs.
Technology-Focused resume experience section
A technology-focused big data engineer resume experience section should seamlessly convey not only your technical achievements but also how they contribute to larger business objectives. By highlighting your mastery over various technologies and your role in solving complex problems, you demonstrate your ability to effectively manage large datasets. It's equally important to showcase your collaboration with data scientists and other engineers, as this reveals your teamwork skills alongside your technical abilities.
Begin by listing your job title, workplace, and the dates of your employment. Then, ensure your bullet points detail your responsibilities and accomplishments in a way that is both succinct and informative. Highlighting your success in optimizing data processing systems, improving data quality, and contributing to impactful projects is key. These points should also illustrate your expertise in data architecture and analysis, along with specific software or programming languages you've used. This approach ensures that your contributions are clearly understood and appreciated by potential employers.
Big Data Engineer
Tech Innovations Inc.
June 2021 - Present
- Engineered and maintained data pipelines with Apache Spark, improving processing time by 60%.
- Implemented data validation processes, enhancing data quality for analytics and reducing errors by 30%.
- Collaborated with data science team to deploy ML models, boosting predictive accuracy by 20%.
- Designed scalable data storage solutions, reducing storage costs by 25% while maintaining performance.
Customer-Focused resume experience section
A customer-focused big data engineer resume experience section should effectively highlight your ability to manage large datasets in a way that prioritizes customer needs. Begin with your major achievements and projects that had a direct positive impact on customer satisfaction. Providing specific metrics or outcomes gives tangible proof of your success, making your accomplishments more credible to employers. Present your experiences with bullet points for clarity, ensuring each entry emphasizes how your work addressed customer needs.
Your role in developing data solutions that tackled customer issues or boosted service delivery is crucial. Use action verbs like "developed," "enhanced," or "optimized" to underline your active role. Additionally, mentioning your collaboration with various teams to align data insights with customer requirements can illustrate your value to potential employers. This approach helps them see how you connect insights to actionable results that benefit customers.
Big Data Engineer
Tech Innovations Inc.
January 2020 - Present
- Developed a predictive analytics model that reduced customer churn by 15%, boosting retention strategies.
- Designed and implemented a real-time data pipeline, improving data processing speed by 30% and allowing quicker customer service response.
- Worked with product and marketing teams to create data-driven personalized customer experiences, increasing user engagement by 25%.
- Analyzed customer feedback data to pinpoint key issues, leading to a 20% boost in customer satisfaction scores.
Write your big data engineer resume summary section
A big-data-focused resume summary should grab attention and highlight what makes you unique as a big data engineer. Use clear and concise language to showcase your standout skills and experience. Engage the reader quickly by emphasizing your data analysis, database management, and proficiency in big data technologies. While technical prowess is vital, don't overlook the importance of soft skills like problem-solving and teamwork. Ensure your summary reflects your career achievements and demonstrates how they align with the job you're targeting. Consider this example of a resume summary for a big data engineer:
This example effectively captures attention by immediately stating relevant experience and showcasing technical skills alongside a quantifiable achievement. Including teamwork and business outcomes rounds out your professional profile, connecting your abilities to real-world impact. Understanding the differences between resume elements is crucial. A summary offers a quick snapshot of your career and expertise, ideal for those with experience. In contrast, a resume objective outlines career goals, suitable for newcomers to a field. A resume profile acts similarly to a summary but offers more structural flexibility. Meanwhile, a summary of qualifications highlights key achievements and technical skills, often in bullet points. Select the option that best fits your career level and the job you're pursuing.
Listing your big data engineer skills on your resume
A skills-focused big data engineer resume should strategically present your abilities to capture and keep the reader’s attention. Consider having a dedicated skills section while also embedding relevant skills within your experience and summary sections. This dual approach ensures that you highlight both technical and interpersonal skills. Strengths and soft skills describe your personal traits and how you collaborate with others. In contrast, hard skills are the measurable technical abilities you possess, like coding proficiency or data analysis expertise.
Effectively using skills and strengths as keywords can significantly impact your resume’s visibility. These keywords are crucial for passing through Applicant Tracking Systems (ATS) and catching the eye of recruiters, aligning your skill set with what organizations need. Think of the skills section as a snapshot that showcases the depth and breadth of your experience.
Here’s an example of how a dedicated skills section might look for a big data engineer:
This skills section is highly effective because it delivers a targeted view of your expertise. It's succinct and focuses directly on the essential skills for a big data engineer role.
Best hard skills to feature on your big data engineer resume
The hard skills you list should clearly demonstrate your ability to work with complex datasets and advanced technologies. These skills communicate your technical competence to potential employers, ensuring they see you as a capable data engineer.
Hard Skills
- Apache Hadoop
- Apache Spark
- Python Programming
- SQL
- Data Warehousing
- NoSQL Databases
- ETL Processes
- Cloud Platforms (AWS, Azure)
- Machine Learning
- Data Visualization
- Scala
- Java
- Distributed Systems
- Data Mining
- Apache Kafka
Best soft skills to feature on your big data engineer resume
Your soft skills should showcase your ability to work well with others and handle project challenges. These skills highlight not just your technical acumen, but also your potential as a collaborative team member and problem-solver.
Soft Skills
- Problem-Solving
- Communication
- Teamwork
- Adaptability
- Critical Thinking
- Time Management
- Attention to Detail
- Creativity
- Leadership
- Decision Making
- Analytical Skills
- Conflict Resolution
- Interpersonal Skills
- Emotional Intelligence
- Initiative
How to include your education on your resume
Your education section is an essential piece of your big data engineer resume. This is where you're able to demonstrate the formal training that underpins your technical skills. Tailor your education section to the job you're applying for by focusing only on relevant qualifications. Including unrelated education details can distract hiring managers from your strengths.
It's important to present your GPA if it's impressive, especially if you're a recent graduate. List your GPA as a number, such as "GPA: 3.8/4.0". If you graduated with honors, you can add "cum laude" next to your degree to highlight your achievement. When listing your degree, include the full title, like "Bachelor of Science in Computer Science."
Here's a wrong and right example of an education section for a big data engineer:
Wrong example:
08/2010 - 05/2014 Right example:
08/2016 - 05/2020 The right example succeeds because it focuses on a degree relevant to the big data field, rightly omitting irrelevant coursework. The GPA and honor distinction give concrete evidence of academic excellence, supporting your capability as a big data engineer. This polished approach resonates strongly with potential employers.
How to include big data engineer certificates on your resume
Including a certificates section on your big data engineer resume is crucial. Certificates showcase your expertise and commitment to the field. You can list certificates in the header to catch the hiring manager's eye.
List the name of the certificate first. Include the date when you earned it. Add the issuing organization to give it credibility. For example:
A standalone certificates section offers a clear view of your qualifications. It highlights your dedication to improving your skills. For example:
[here was the JSON object 2]
This section looks good because it contains relevant certificates for a big data engineer role. These certificates show your knowledge in key areas like data engineering and data science. Listing the issuing organization adds trust and value.
Extra sections to include in your big data engineer resume
In today's competitive job market, a well-rounded resume can set you apart from other candidates. As a big data engineer, you have the technical skills needed, but additional sections on your resume can highlight your diverse abilities and interests.
- Languages — Highlight your proficiency in multiple languages to demonstrate your ability to communicate in diverse environments. This skill can be particularly beneficial when dealing with international teams or clients.
- Hobbies and interests — Include your hobbies and interests to show a more personal side and balance out the technical aspect of your resume. This can also help to connect with potential employers on a human level, making your resume more memorable.
- Volunteer work — List your volunteer experiences to show your commitment to community service and willingness to contribute beyond your professional responsibilities. This can enhance your resume by reflecting your leadership skills and ethical values.
- Books — Mention influential books you've read to provide insight into your continuous learning and knowledge base. This can also indicate your areas of interest and the breadth of your understanding within the industry.
By including these sections, your resume will reflect not just your technical expertise but also your well-rounded personality, making you a compelling candidate for a big data engineering position.
In Conclusion
In conclusion, your big data engineer resume is your professional introduction, setting the stage for potential employment opportunities. This detailed guide has outlined the critical components of crafting an effective resume that highlights your technical skills and achievements. By focusing on clear organization, utilizing a professional resume template, and choosing the right format, you can ensure your resume is not only visually appealing but also informative. Emphasizing both your technical and soft skills through quantifiable results demonstrates your ability to make a tangible impact in previous roles. Furthermore, showcasing your education and relevant certifications adds credibility, evidencing your knowledge and commitment to the field.
Make sure to tailor each section of your resume to reflect the specific job you're applying for. This approach maximizes your chances of standing out among competitors. Including extra sections like languages, hobbies, or volunteer work can give a more personal touch, showcasing a well-rounded you. Always aim for clarity, precision, and relevance to ensure the recruiter understands your expertise and potential contributions. Whether you are an experienced big data engineer or just starting, presenting a resume with these elements will substantially enhance your prospects. Keep this guide as your reference, and approach the job market with confidence, knowing your resume is a clear and powerful representation of your professional journey.
Related Articles

Continue Reading
Check more recommended readings to get the job of your dreams.
Resume
Resources
Tools
© 2026. All rights reserved.
Made with love by people who care.